Menu
NEW AGENT
MY AGENTS
ASSISTANTS
Step 1:
AI Digest Monthly Report
1️⃣
Perfect output
- scan ALL
2️⃣ Add
output numbers
, then...
3️⃣ Add
Subagent Numbers
(work backwards
from output number!
)
4️⃣ Add
ACTUAL Skills
to subagent
✅ DONE..Copy x4 to Step 3...
SETTINGS
LOGOUT
What Shall We Build Next?
1
Describe
Describe your task
2
Refine
Refine the plan
3
SubAgents
Review all agents
4
Deploy
Deploy your agent
Sub Agent 1
Sub Agent 2
Sub Agent 3
Sub Agent 4
Sub Agent 5
Sub Agent 6
Sub Agent 7
Sub Agent 8
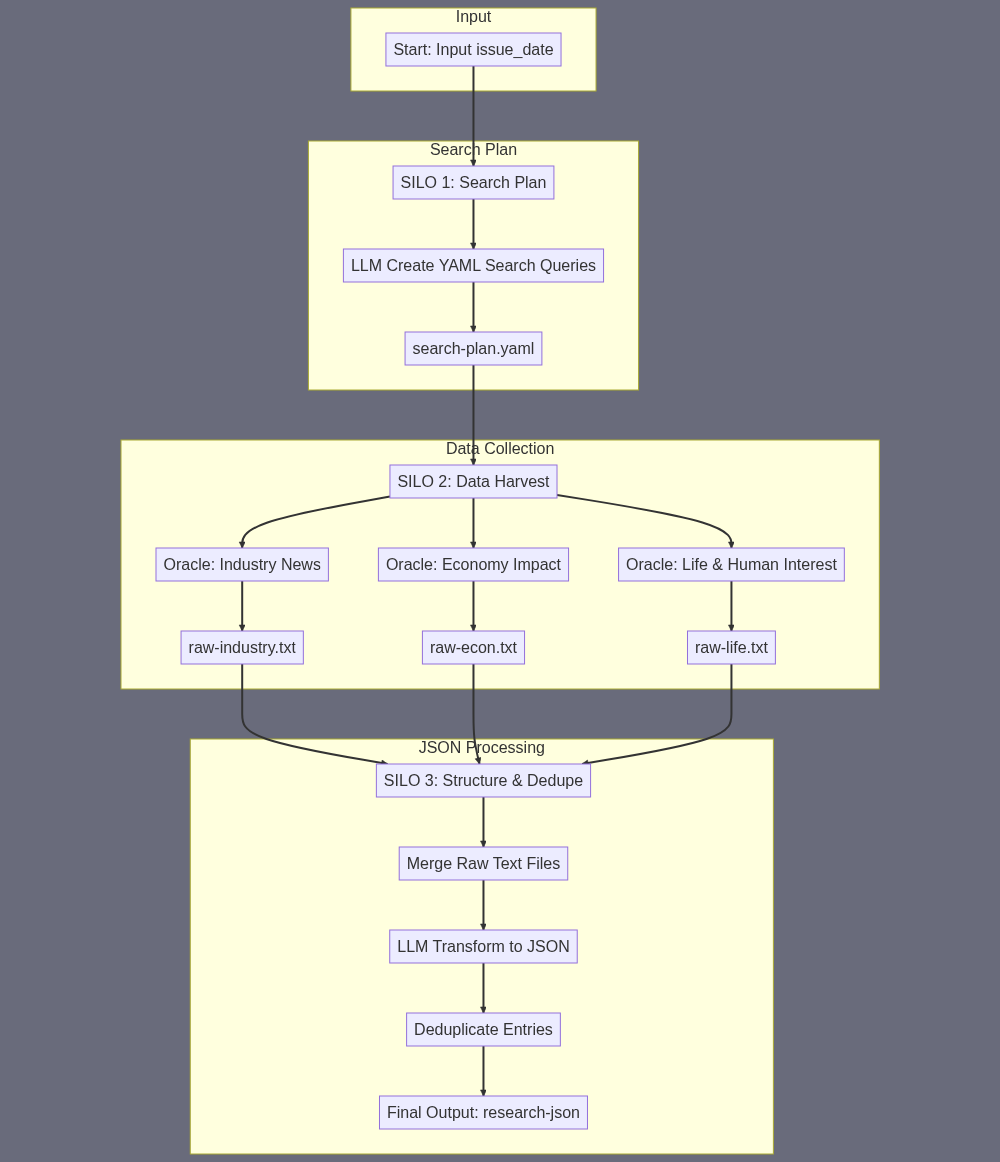
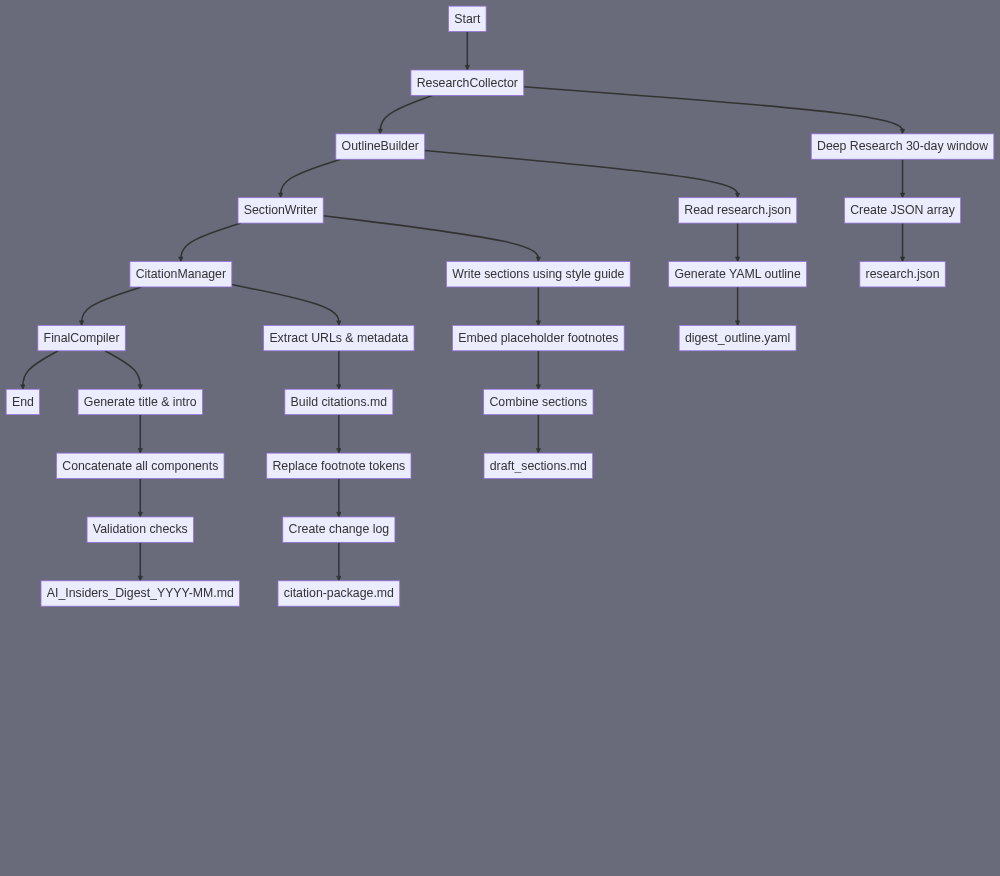
A) SUBAGENT SUMMARY ResearchCollector scans the last 30 days of AI–related news/events and returns one consolidated JSON file containing all source items (headline, date, URL, 100-word abstract, tags, etc.) that will feed every later writing step. B) FINAL TASK OUTPUT [research-json] → a UTF-8 JSON array file (≈120–200 items, ≤1 MB) with this exact schema per element: { "id": "R###", // sequential (R001 …) "category": "industry | economy | life | human-interest", "company_or_topic": "OpenAI | Nvidia | …", "headline": "string", "summary": "≤100 words", "date": "YYYY-MM-DD", "url": "https://…", "source": "NYTimes | TechCrunch …" } C) SUBAGENT INPUT {issue_date} (YYYY-MM-DD, always invoked on or before the 25th of a month) E) SUBAGENT TASK SUMMARY 1. Build 30-day search blueprint {issue_date} → #223 Powerful LLM Prompt-to-Text Prompt: “It is {issue_date}. Create a YAML list of 15 AI-related search queries covering: • core companies (OpenAI, Nvidia, Anthropic, Google, Amazon, Microsoft, Meta) • any new/emerging AI firms that made headlines in the last 30 days • AI & global/US economy impacts • AI & tech-industry shifts • AI influence on everyday life & society • at least 3 ‘positive human-interest’ AI success stories For each item give: id, query, target category.” Output ⇒ [search-plan.yaml] 2. Collect source items (run three Oracle sweeps, max 5 questions each) a) Industry/Company news [search-plan.yaml] → #224 Oracle Ask A Question (feed the 5 industry-company queries) → [raw-industry.txt] b) Economy/Tech impact #224 Oracle Ask A Question (feed the 5 economy/tech queries) → [raw-econ.txt] c) Everyday life & human-interest #224 Oracle Ask A Question (feed the 5 life/human-interest queries) → [raw-life.txt] Each Oracle call is instructed to: “Return a bullet list (max 40 bullets) where each bullet contains: • headline (≤120 chars) – date – source – canonical URL – 2-sentence summary” 3. Normalise & merge into structured JSON Concatenate [raw-industry.txt] + [raw-econ.txt] + [raw-life.txt] → [all-raw.txt] [all-raw.txt] → #223 Powerful LLM Prompt-to-Text Prompt: “Transform the bullet list into a single JSON array using the target schema. • Assign unique ids starting R001… • Map bullets to category using heuristics (industry, economy, life, human-interest). • Truncate summaries to 100 words. • Remove duplicates (same URL).” Output ⇒ [research-json] F) SILOS SILO 1 – Search-Plan Generation {issue_date} → #223 → [search-plan.yaml] SILO 2 – Data Harvesting For each of the three thematic groups run #224 Oracle → [raw-*.txt] SILO 3 – Structuring & Deduplication Merge raw outputs → #223 → [research-json]
SubAgent #1 - Diagram
Expand Diagram
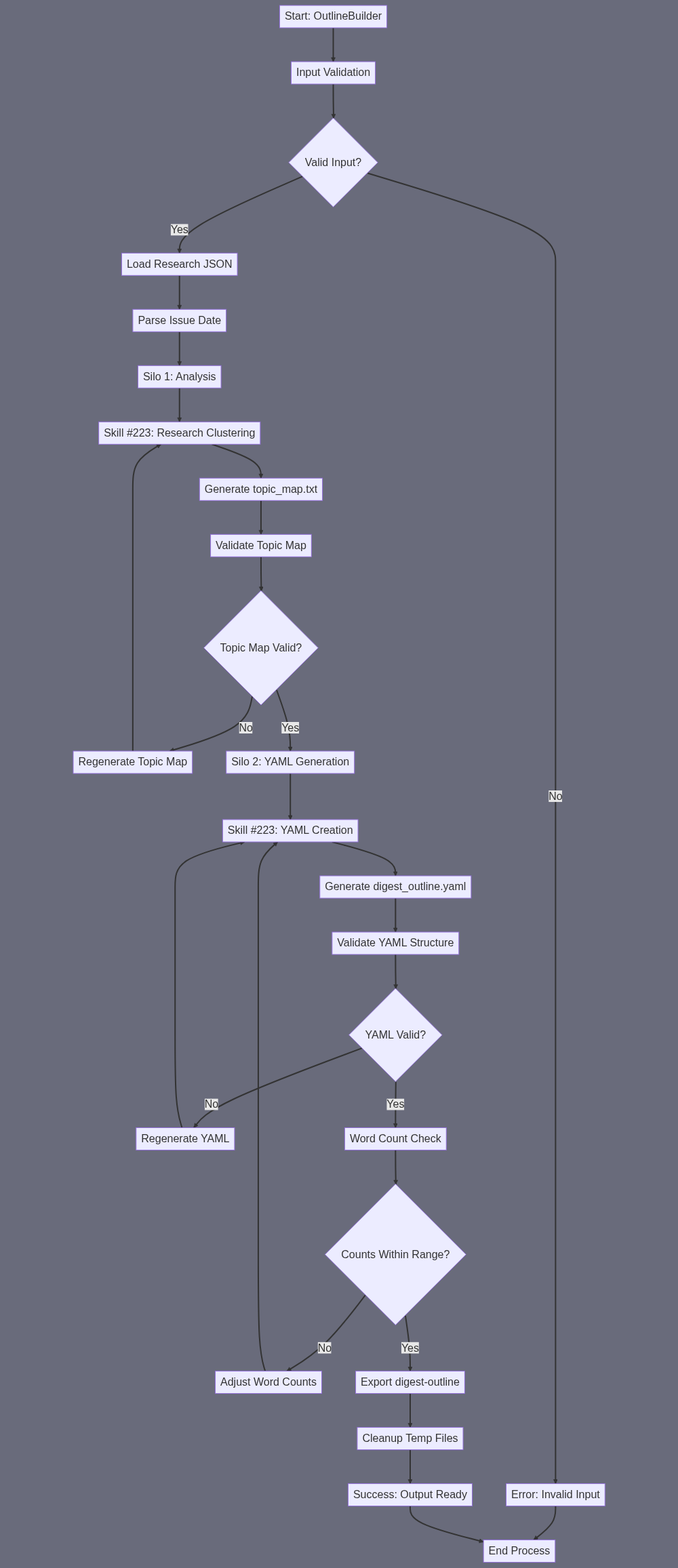
A) SUBAGENT SUMMARY “OutlineBuilder” converts the raw monthly research dump into a single, well-structured YAML blueprint that the downstream writer can follow. B) FINAL TASK OUTPUT [digest-outline] → digest_outline.yaml • UTF-8 text file, valid YAML 1.2 • ≈1–3 KB (≈120–250 lines) • Top-level keys: meta, section_1, section_2, section_3 • For every section: title, target_words, 4-8 subtopics (each with: subtitle, target_words, research_ids[]) • Explicit placeholders: human_interest_story (section 2) & monetisation_idea (section 3) C) SUBAGENT INPUT {issue_date} (string, e.g. “2024-07”) [research-json] (research.json – array of objects with id, type, headline, summary, date, url) E) SUBAGENT TASK SUMMARY {issue_date} + [research-json] │ ├─ Skill #223 (Powerful LLM Prompt-to-Text) → topic_map.txt │ Prompt: │ 1. Load research-json (pasted verbatim). │ 2. Cluster items into three buckets: “Industry News”, “AI in the Real World”, “Monetisation”. │ 3. Within each bucket, suggest 4-8 logical subtopics; list matching research.ids for each. │ 4. Estimate word count per subtopic so that each bucket totals 3 000-4 000 words. │ 5. Return plain-text table only. │ └─ Skill #223 (Powerful LLM Prompt-to-Text) → digest_outline.yaml [FINAL OUTPUT] Prompt: “Using the topic_map.txt above, create valid YAML exactly as follows: meta: issue_date: <{issue_date}> section_1: title: ‘Industry news & updates’ target_words: <sum> subtopics: - subtitle: … target_words: … research_ids: […] … (repeat for all subtopics)… section_2: title: ‘AI in the real world’ target_words: <sum> human_interest_story: “TBD” subtopics: … section_3: title: ‘Make money with AI’ target_words: <sum> monetisation_idea: “TBD” subtopics: … Return only YAML, no commentary. Validate indentation (2 spaces).” F) SILOS Silo 1 – Analyse & Cluster Skill #223 → topic_map.txt (internal helper file) Silo 2 – Generate YAML Blueprint Skill #223 → digest_outline.yaml (exported as [digest-outline])
SubAgent #2 - Diagram
Expand Diagram
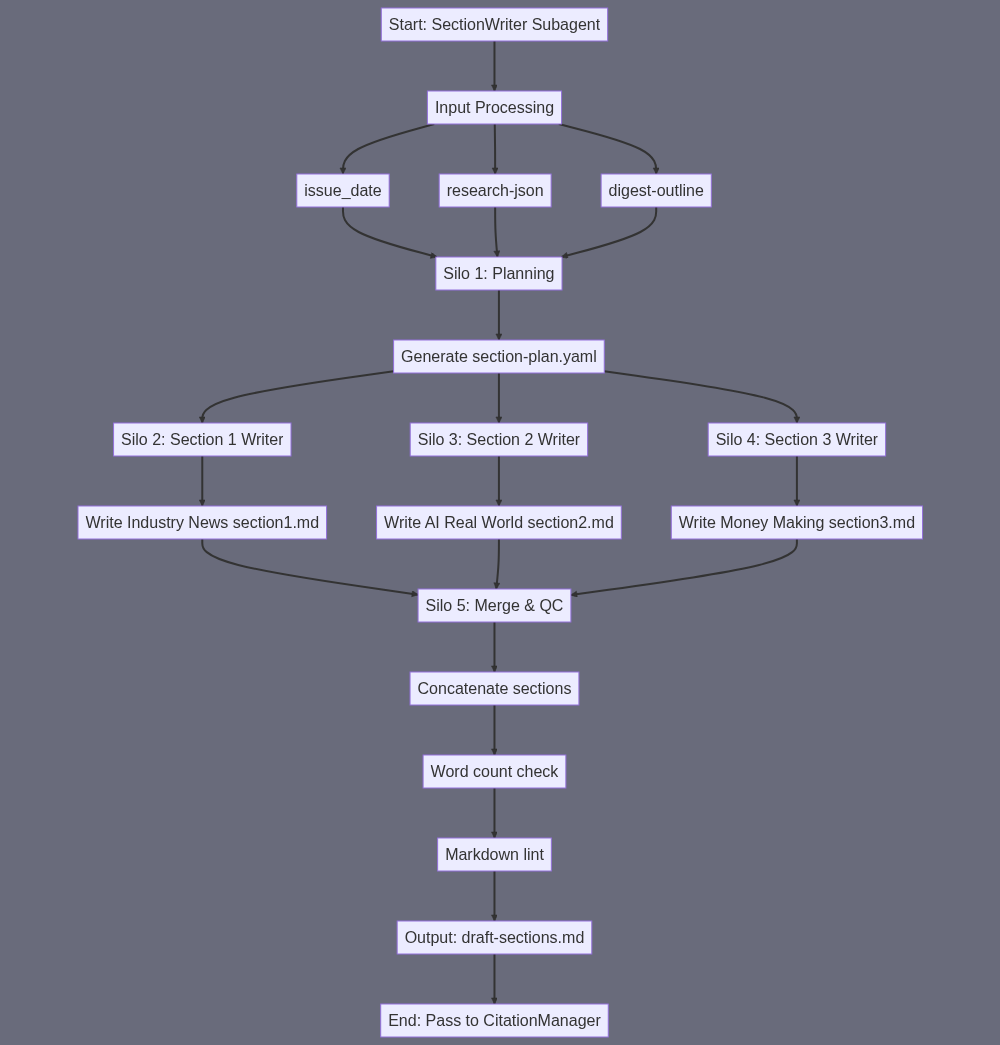
A) SUBAGENT SUMMARY “SectionWriter” turns the outline + research bundle for the month into three long-form, foot-note-ready Markdown sections that total ±9-12 k words. B) FINAL TASK OUTPUT [draft-sections] → a single UTF-8 Markdown file named AI_Insiders_Digest_{issue_date}_draft_sections.md • Contains only the three numbered H2 sections (no title/intro) • Each section ≈3 000–4 000 words • Inline placeholder footnotes in the form [^id] where id == research-json.id • Clean Markdown (H2 section heads, H3/H4 as needed, lists, code-blocks, etc.) C) SUBAGENT INPUT {issue_date} (string, e.g. “2024-07”) [research-json] (JSON array produced by ResearchCollector) [digest-outline] (YAML blueprint produced by OutlineBuilder) E) SUBAGENT TASK SUMMARY {issue_date} + [research-json] + [digest-outline] → #223 “Prompt-to-Text” Task: build a “section-plan.yaml” that, for each of the three sections, lists: • target word-count range, • sub-headings sequence, • bullet summary of core arguments, • which research-json ids must be cited where. Output → (section-plan) (section-plan, research-json) → #190 “Write/Re-write Text” (Silo 2 – Section 1 Writer) Prompt: “Using the provided plan for Section 1 (‘Industry news & updates’), write ≈3 500-word Markdown section, embed [^id] after each fact that maps to research id. Follow house style…” Output → (section1.md) (section-plan, research-json) → #190 “Write/Re-write Text” (Silo 3 – Section 2 Writer) Prompt analogous to above (“AI in the real world” + end with human-interest story) Output → (section2.md) (section-plan, research-json) → #190 “Write/Re-write Text” (Silo 4 – Section 3 Writer) Prompt analogous to above (“Make money with AI” for solopreneurs) Output → (section3.md) (section1.md + section2.md + section3.md) → #223 “Prompt-to-Text” (Silo 5 – Combine & QC) Prompt: “Concatenate the three files in numeric order under H2 headings exactly as: ‘## 1. Industry news & updates’, etc. Ensure total words 9 000–12 000 (±5%). Run a quick lint for Markdown, keep placeholder footnotes unchanged.” Output → AI_Insiders_Digest_{issue_date}_draft_sections.md == [draft-sections] F) SILOS Silo 1 – Planning Input: outline + research → #223 → section-plan.yaml Silo 2 – Write Section 1 Input: section-plan + research → #190 → section1.md Silo 3 – Write Section 2 Input: section-plan + research → #190 → section2.md Silo 4 – Write Section 3 Input: section-plan + research → #190 → section3.md Silo 5 – Merge & QC Input: section1.md, section2.md, section3.md → #223 → [draft-sections] No additional skills are necessary; the chain satisfies required inputs/outputs and hands off a single well-formed Markdown file to the next subagent (CitationManager).
SubAgent #3 - Diagram
Expand Flow
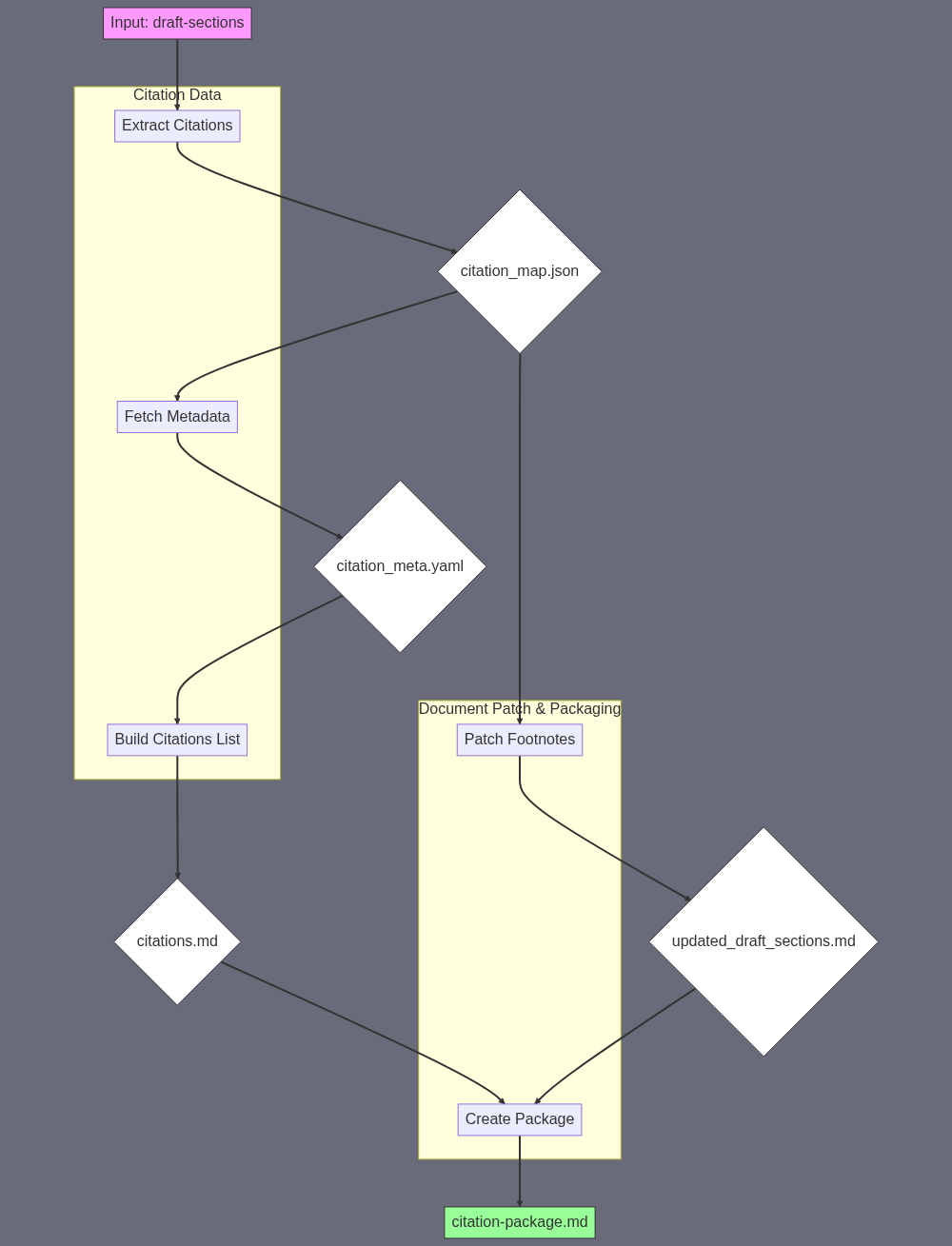
A) SUBAGENT SUMMARY CitationManager turns the raw draft with placeholder foot-notes into a publication-ready version with numbered foot-notes, a standalone, alphabetised citations list, and a compact change-log bundled as citation-package.md. ─────────────────────────────────────────── B) FINAL TASK OUTPUT • updated_draft_sections.md (≈9–12 k words, all [^id] tokens replaced by sequential numeric foot-notes that point to the citations list) • citations.md (Markdown list of foot-notes 1…N, each entry: Title. Source / Publisher – URL – date) • citation-package.md ≈300 words total, containing 1. 100-word change-log (what changed & why) 2. the full contents of citations.md 3. a one-line pointer: “Updated content file: updated_draft_sections.md” (The three files are saved in the working directory; citation-package.md is the formal sub-agent output that “points to” the other two.) ─────────────────────────────────────────── C) SUBAGENT INPUT [draft-sections] → single Markdown file coming from Sub-agent 3 ─────────────────────────────────────────── E) SUBAGENT TASK SUMMARY (skill chain) INPUT [draft-sections] └─► 1. SKILL #223 – “Prompt-to-Text: extract citation map” • Prompt: “Read the Markdown below. For every placeholder foot-note token in the form [^xyz] or [^123] identify → a) the exact token, b) any URL(s) that occur in the same sentence/paragraph, c) 15-word context snippet. Return JSON array [{token, url, context}].” • OUTPUT → citation_map.json citation_map.json └─► 2. SKILL #224 – “Oracle Ask a Question: fetch metadata” • Prompt: “For each URL inside this JSON, return: full article title, site/publisher, author (if present), original publication date (ISO-8601). Return as YAML keyed by URL.” • OUTPUT → citation_meta.yaml citation_map.json + citation_meta.yaml └─► 3. SKILL #223 – “Prompt-to-Text: build citations list” • Prompt: “Merge the two inputs. Produce a Markdown foot-note list numbered 1…N in the order URLs first appear in draft. Each line style: [^n]: Title. Publisher – URL – PubDate.” • OUTPUT → citations.md [draft-sections] + citation_map.json └─► 4. SKILL #190 – “Write/Re-write Text: patch foot-notes” • Prompt: “Replace every placeholder in Draft with its corresponding sequential number from the map (maintain Markdown). Output the fully updated text.” • OUTPUT → updated_draft_sections.md updated_draft_sections.md + citations.md └─► 5. SKILL #223 – “Prompt-to-Text: create change-log & assemble package” • Prompt: 1. Write a 100-word change-log explaining what CitationManager did this run (dates, counts, major fixes). 2. Append the full citations.md. 3. Finish with the line: “Updated content file: updated_draft_sections.md”. • OUTPUT → citation-package.md ❰FINAL OUTPUT❱ ─────────────────────────────────────────── F) SILOS SILO 1 – “Citation Data” Step 1 (#223) → Step 2 (#224) → Step 3 (#223) Purpose: extract URLs, fetch metadata, format numbered citations list. SILO 2 – “Document Patch & Packaging” Step 4 (#190) → Step 5 (#223) Purpose: inject numbered foot-notes into the draft and wrap everything into citation-package.md. The two silos together satisfy the required output specification while preserving clear, debuggable stages.
4 Template & Links
Expand Flow
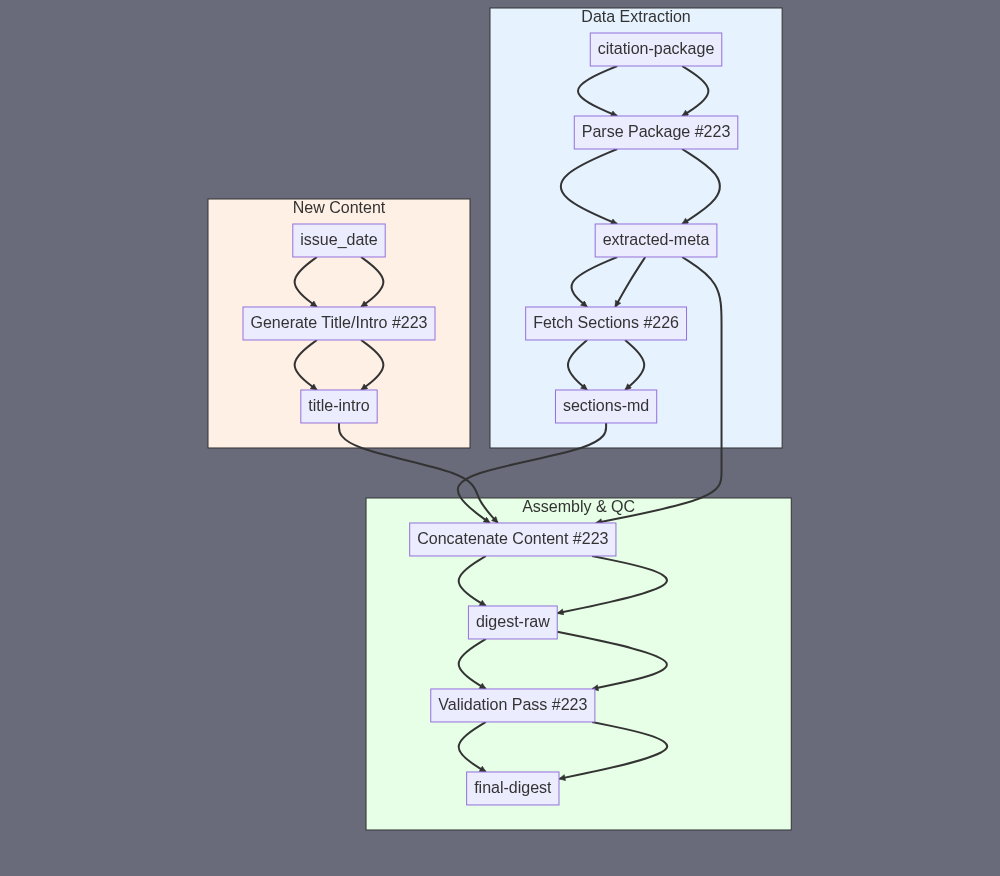
A) SUBAGENT SUMMARY “FinalCompiler” turns the edited section-draft + citation bundle into one publish-ready, linted, 9–12 k-word Markdown newsletter. B) FINAL TASK OUTPUT [final-digest] → AI_Insiders_Digest_{YYYY-MM}.md • UTF-8 Markdown, ≤ 250 KB, 9 000-12 000 words • H1 title, ±200-word intro, three numbered H2 sections (already foot-noted), H1 “Sources” followed by numbered citations list • All intra-doc links & footnote references resolve; no external assets required C) SUBAGENT INPUT {issue_date} (string, e.g. “2024-07”) [citation-package] (markdown file that contains a) 100-word change-log b) embedded “citations.md” block c) pointer/URL to updated_draft_sections.md) E) SUBAGENT TASK SUMMARY {issue_date} + [citation-package] → #223 Parse citation-package, return JSON with: • change_log (ignored here) • citations_markdown (string) • sections_url (URL) ⇒ [extracted-meta] [extracted-meta].sections_url → #226 Extract Structured Data From 1x URL – fetch full text of updated_draft_sections.md ⇒ [sections-md] {issue_date} → #223 Generate newsletter H1 title (“AI Insider’s Digest – {Month YYYY}”) + ~200-word engaging intro ⇒ [title-intro] [title-intro] + [sections-md] + [extracted-meta].citations_markdown → #223 Concatenate exactly in order: 1) H1 title 2) intro paragraph(s) 3) sections-md content (already contains H2/H3 headings) 4) blank line, H1 “Sources” 5) citations_markdown Return single Markdown string ⇒ [digest-raw] [digest-raw] → #223 Validation-pass prompt: • Count words; ensure 9–12 k (expand/trim if outside) • Run simple Markdown lint rules (heading order, trailing spaces, blank-line spacing) • Scan each http/https link format; flag obvious typos (eg “htp://”) • Fix any detected issues automatically Return final Markdown ⇒ [final-digest] F) SILOS Silo 1 – Data Extraction [citation-package] → #223 (parse) → #226 (fetch sections) Silo 2 – New Content {issue_date} → #223 (title & intro) Silo 3 – Assembly & QC Concatenate (#223) → Validate & Fix (#223) → [final-digest]
5 Template & Links
Expand Flow
there is no subagent 6
6 Template & Links
Expand Flow
Templates & Links Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
7 Template & Links
Expand Flow
Questions & Research Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
8 Template & Links
Expand Flow
Templates & Links Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
9 Template & Links
Expand Flow
Templates & Links Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
10 Template & Links
Expand Flow
Questions & Research Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
11 Template & Links
Expand Flow
Templates & Links Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
12 Template & Links
Expand Flow
Need To Start Afresh?
BACK TO REFINE
Tweaked & Good To Go?
PROCEED TO DEPLOY