Menu
NEW AGENT
MY AGENTS
ASSISTANTS
Step 1:
Topical Avatar Video Creator
1️⃣
Perfect output
- scan ALL
2️⃣ Add
output numbers
, then...
3️⃣ Add
Subagent Numbers
(work backwards
from output number!
)
4️⃣ Add
ACTUAL Skills
to subagent
✅ DONE..Copy x4 to Step 3...
SETTINGS
LOGOUT
What Shall We Build Next?
1
Describe
Describe your task
2
Refine
Refine the plan
3
SubAgents
Review all agents
4
Deploy
Deploy your agent
Sub Agent 1
Sub Agent 2
Sub Agent 3
Sub Agent 4
Sub Agent 5
Sub Agent 6
Sub Agent 7
Sub Agent 8
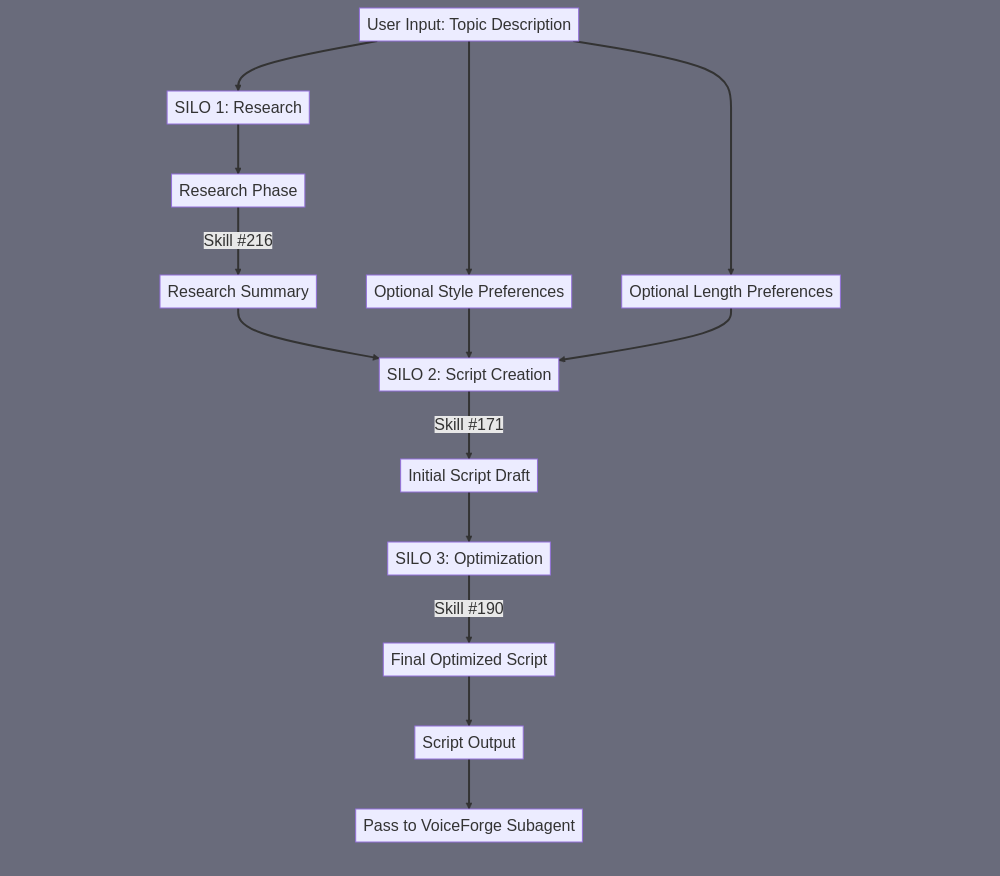
Let me break down the ScriptMaster subagent in detail: A) SUBAGENT SUMMARY: ScriptMaster takes a user's topic description and generates an optimized, natural-sounding voice-over script specifically designed for talking head videos, with appropriate pacing, tone, and length (100-300 words). B) FINAL TASK OUTPUT: A text file containing a professionally formatted voice-over script, structured with proper timing breaks, approximately 100-300 words in length, optimized for natural speech patterns and talking head delivery. C) SUBAGENT INPUT: 1. User's topic/theme description 2. Optional style preferences (tone, formality, etc.) 3. Optional length preference (within 100-300 word range) E) SUBAGENT TASK SUMMARY: The workflow involves three main chained steps: 1. Research Phase: INPUT: User topic description > SKILL #216 (Research Topic Deeply) > OUTPUT: Comprehensive research summary 2. Initial Script Generation: INPUT: Research summary > SKILL #171 (Write Voice Over Script Based On Instructions) > OUTPUT: First draft of voice-over script 3. Script Optimization: INPUT: First draft script > SKILL #190 (Write or rewrite text based on instructions) with specific prompt for talking head optimization > OUTPUT: Final optimized script F) SILOS: This subagent operates in three distinct silos: SILO 1: RESEARCH • Purpose: Gather comprehensive topic information • Input: User topic description • Skill: #216 (Research Topic Deeply) • Output: Research summary (1000-3000 characters) SILO 2: SCRIPT CREATION • Purpose: Transform research into initial script • Input: Research summary from Silo 1 • Skill: #171 (Write Voice Over Script Based On Instructions) • Output: Initial script draft SILO 3: OPTIMIZATION • Purpose: Optimize script for talking head delivery • Input: Initial script from Silo 2 • Skill: #190 (Write or rewrite text based on instructions) • Output: Final optimized script Each silo's output becomes the input for the next silo, creating a refined progression toward the final script. This structure ensures thorough research, proper script formatting, and optimization specifically for talking head delivery.
SubAgent #1 - Diagram
Expand Diagram
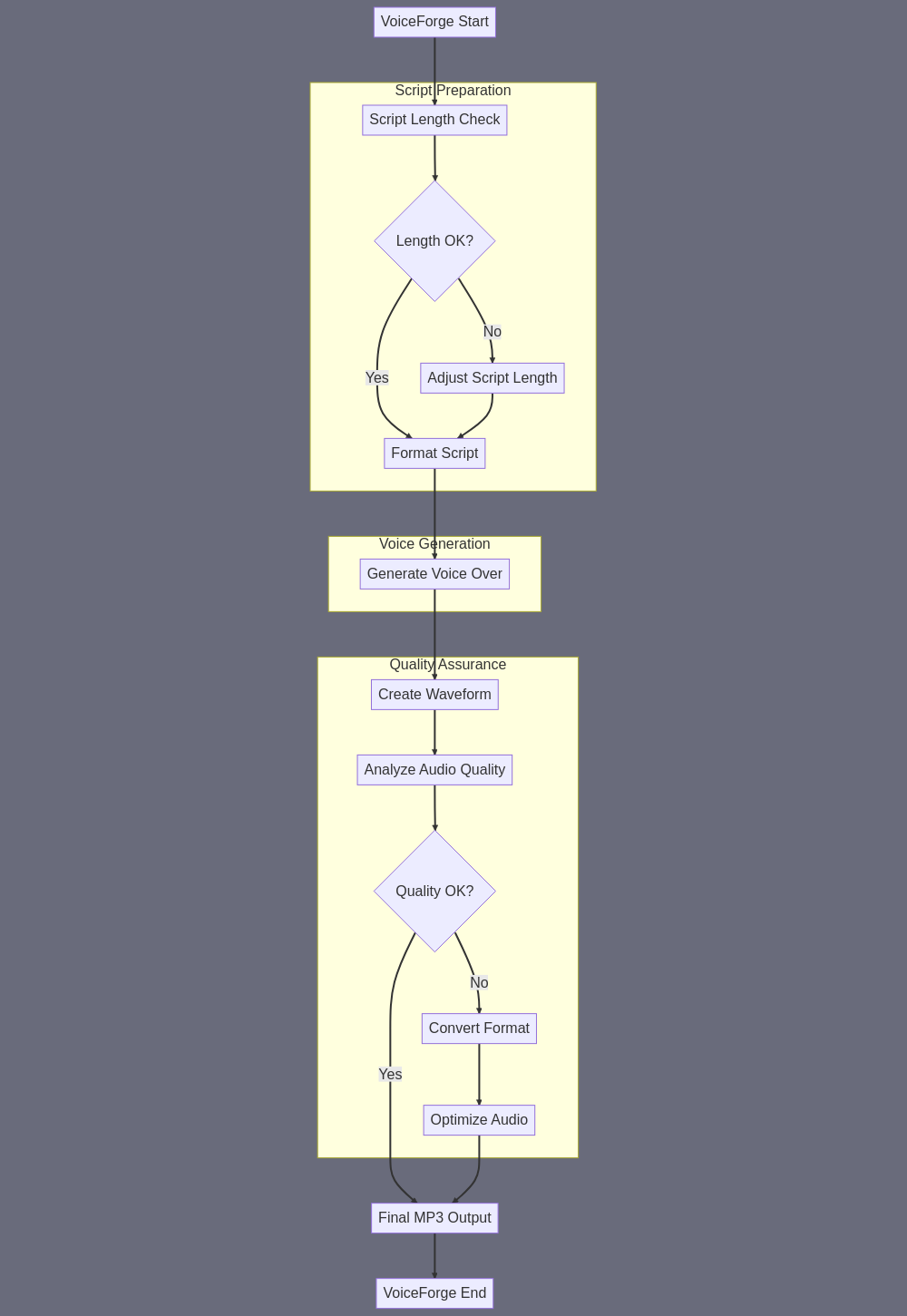
Let me break down the VoiceForge subagent workflow according to the guidelines: A) SUBAGENT SUMMARY: VoiceForge converts a text script into a high-quality voice-over MP3 file, optimizing the script if needed for length constraints and ensuring proper audio output formatting. B) FINAL TASK OUTPUT: An MP3 file URL containing the voice-over audio, specifically formatted for use in a talking head video, with duration between 30 seconds to 5 minutes (based on 100-300 word input script), with clear audio quality suitable for lip-sync processing. C) SUBAGENT INPUT: - Primary Input: Text script (100-300 words) from ScriptMaster subagent - Additional Parameters (if provided): * Voice style preference * Speaking pace/tempo requirements * Any specific pronunciation guides E) SUBAGENT TASK SUMMARY: The workflow follows this sequence: 1. Script Length Verification and Formatting: - Use #190 (Write or rewrite text based on instructions) to verify script length and format if needed * Input: Original script * Output: Formatted script ready for voice conversion 2. Primary Voice Generation: - Use #170 (Turn Script Into Voice Over MP3) to create the voice-over * Input: Formatted script * Output: Initial MP3 URL 3. Audio Quality Check: - Use #179 (Create Visual Waveform Of 60 second Wav/mp3 File) to analyze audio quality * Input: Initial MP3 URL * Output: Waveform visualization 4. Audio Analysis: - Use #176 (Analyze An Image With GPT Vision & Return Text) to review waveform * Input: Waveform visualization * Output: Audio quality analysis 5. If needed, Audio Optimization: - If issues detected, use #178 (Convert 1-20 MP3s to wav) for format conversion * Input: MP3 URL * Output: Final optimized audio file URL F) SILOS: SILO 1: SCRIPT PREPARATION - Input: Raw script - Skill #190: Format/verify script - Output: Formatted script SILO 2: VOICE GENERATION - Input: Formatted script - Skill #170: Generate voice-over - Output: Initial MP3 SILO 3: QUALITY ASSURANCE - Input: Initial MP3 - Skill #179: Generate waveform - Skill #176: Analyze waveform - Skill #178: Optimize if needed - Output: Final MP3 URL This workflow ensures high-quality voice-over generation with built-in quality checks and optimization steps, preparing the audio specifically for use in talking head video generation.
SubAgent #2 - Diagram
Expand Diagram
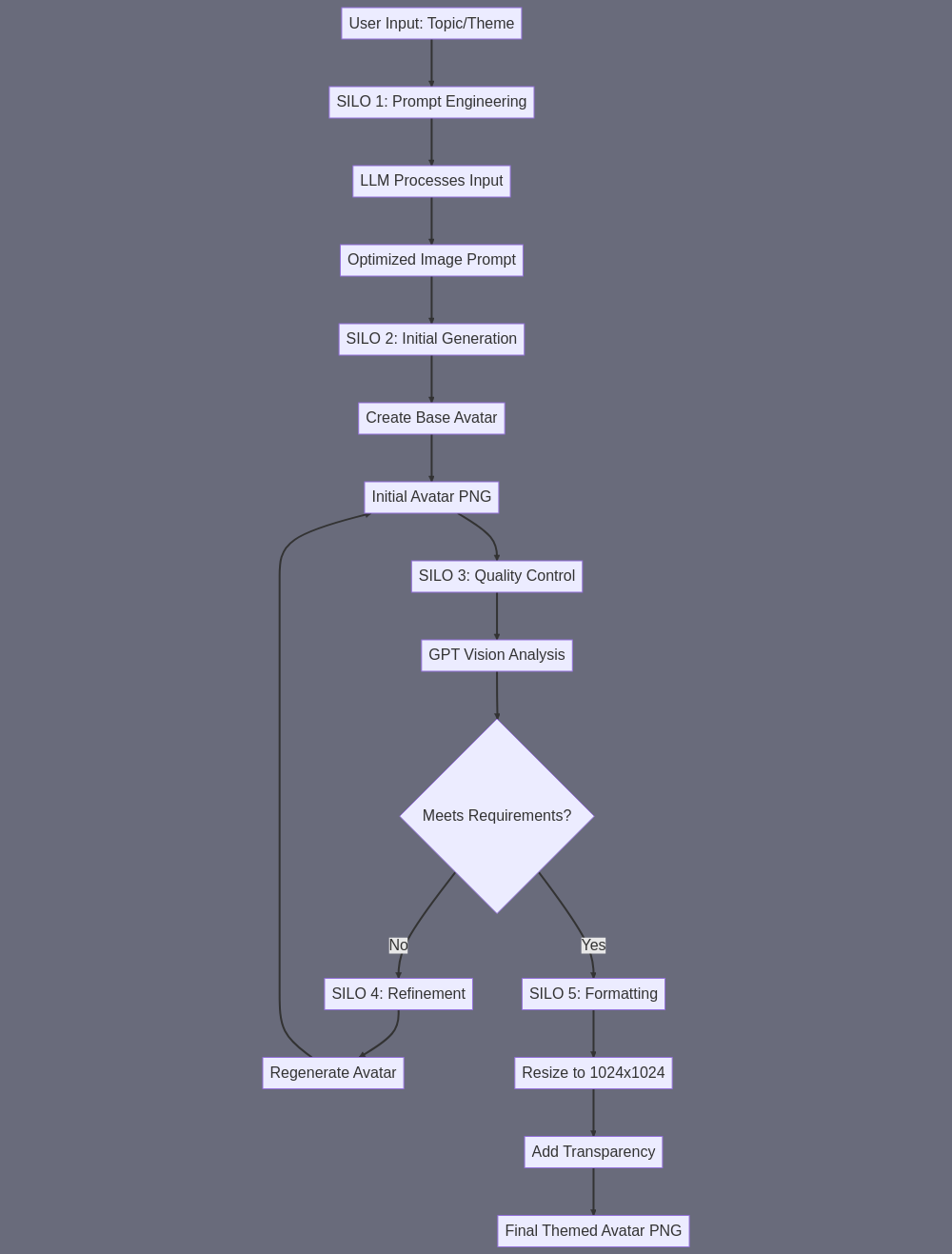
Let me break down the AvatarVision subagent following the requested format: A) SUBAGENT SUMMARY: AvatarVision generates a high-quality, themed AI avatar image that matches the video's topic and maintains consistent visual quality for lip-sync animation, with particular attention to facial features and head positioning. B) FINAL TASK OUTPUT: A 1024x1024 transparent PNG file of a professional-looking avatar head/shoulders shot, with clear facial features (especially mouth area), neutral expression, and clean edges for animation purposes, saved with transparent background. C) SUBAGENT INPUT: 1. Topic/theme description from user 2. Style preferences (professional, casual, specific profession, etc.) 3. Any specific facial feature requirements E) SUBAGENT TASK SUMMARY: The workflow chains together as follows: 1. Start with user input > #223 (Powerful LLM) to generate optimal image generation prompts 2. Generated prompt > #222 (Make Image With Text) to create initial avatar 3. Initial avatar URL > #176 (Analyze Image with GPT Vision) to verify facial features 4. If needed, URL > #221 (Recreate New Image) to refine/adjust 5. Final image > #191 (Resize Image) to ensure 1024x1024 format 6. Output: Final themed-avatar-image.png F) SILOS: SILO 1: PROMPT ENGINEERING - Input: User's topic/theme description - Skill: #223 (Powerful LLM) - Output: Optimized image generation prompt - Purpose: Ensures prompt will generate suitable avatar SILO 2: INITIAL GENERATION - Input: Optimized prompt - Skill: #222 (Make Image With Text) - Output: Initial avatar PNG - Purpose: Creates base avatar image SILO 3: QUALITY CONTROL - Input: Initial avatar PNG - Skill: #176 (Analyze Image with GPT Vision) - Purpose: Verifies facial features suitable for animation - If needed, triggers SILO 4 SILO 4: REFINEMENT (Conditional) - Input: Initial avatar + analysis feedback - Skill: #221 (Recreate New Image) - Output: Refined avatar - Purpose: Improves initial generation if needed SILO 5: FORMATTING - Input: Final avatar (from either SILO 2 or 4) - Skill: #191 (Resize Image) - Output: 1024x1024 transparent PNG - Purpose: Ensures correct format for video generation This structured approach ensures high-quality avatar generation with proper verification and refinement steps, producing an image suitable for lip-sync animation.
SubAgent #3 - Diagram
Expand Flow
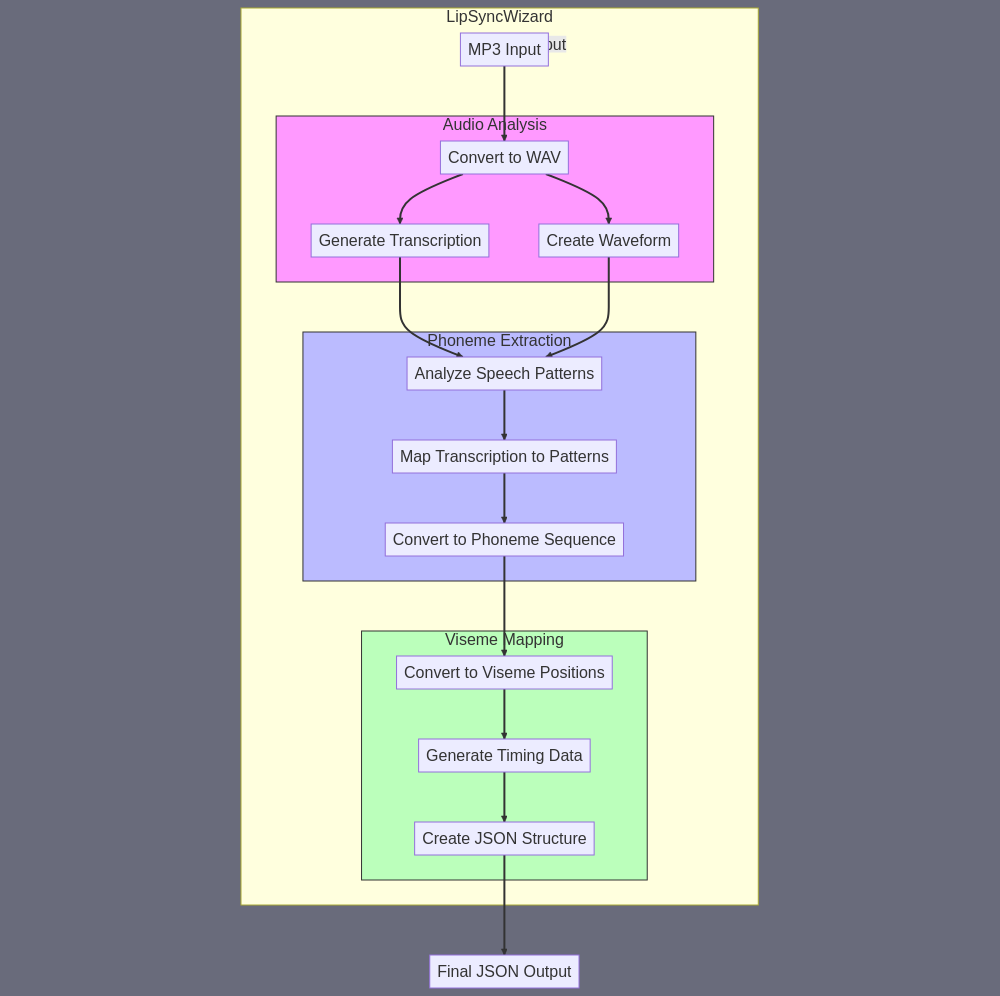
Let me break down the LipSyncWizard subagent in detail: A) SUBAGENT SUMMARY: A specialized component that analyzes an audio file to generate precise phoneme timing data and maps it to corresponding viseme (mouth shape) positions, creating a synchronized animation data stream for avatar lip movement. B) FINAL TASK OUTPUT: A JSON data structure containing time-coded phoneme-to-viseme mappings, including: - Timestamps (in milliseconds) - Phoneme identifiers - Corresponding viseme positions (mouth shapes) - Optional head movement coordinates File format: .json with structured timing data C) SUBAGENT INPUT: - MP3 voice-over file URL - Transcription with word timing data - List of supported visemes for the avatar system D) SUBAGENT TASK SUMMARY: Input > #198 (Get Transcription of MP3 with Timings) > #178 (Convert MP3 to WAV) > #179 (Create Visual Waveform) > #176 (Analyze Waveform with GPT Vision) > #223 (LLM Process Phoneme Data) > JSON Output E) SILOS: The subagent operates in three distinct silos: SILO 1: AUDIO ANALYSIS 1. Convert MP3 to WAV format (#178) 2. Generate precise transcription with timings (#198) 3. Create visual waveform for amplitude analysis (#179) SILO 2: PHONEME EXTRACTION 1. Analyze waveform with GPT Vision (#176) to identify speech patterns 2. Map transcription timings to waveform patterns 3. Use LLM (#223) to convert speech patterns to phoneme sequences SILO 3: VISEME MAPPING 1. Use LLM (#223) to convert phoneme data to viseme positions 2. Generate timing data for mouth movements 3. Create final JSON structure with all synchronized data This breakdown ensures accurate phoneme detection and proper viseme mapping while maintaining precise timing synchronization throughout the process. The final JSON output can then be used by VideoAssemblerPro to create the synchronized talking head animation. Note: This approach uses existing skills creatively to approximate phoneme detection, though a dedicated phoneme detection skill would be ideal for future implementations.
4 Template & Links
Expand Flow
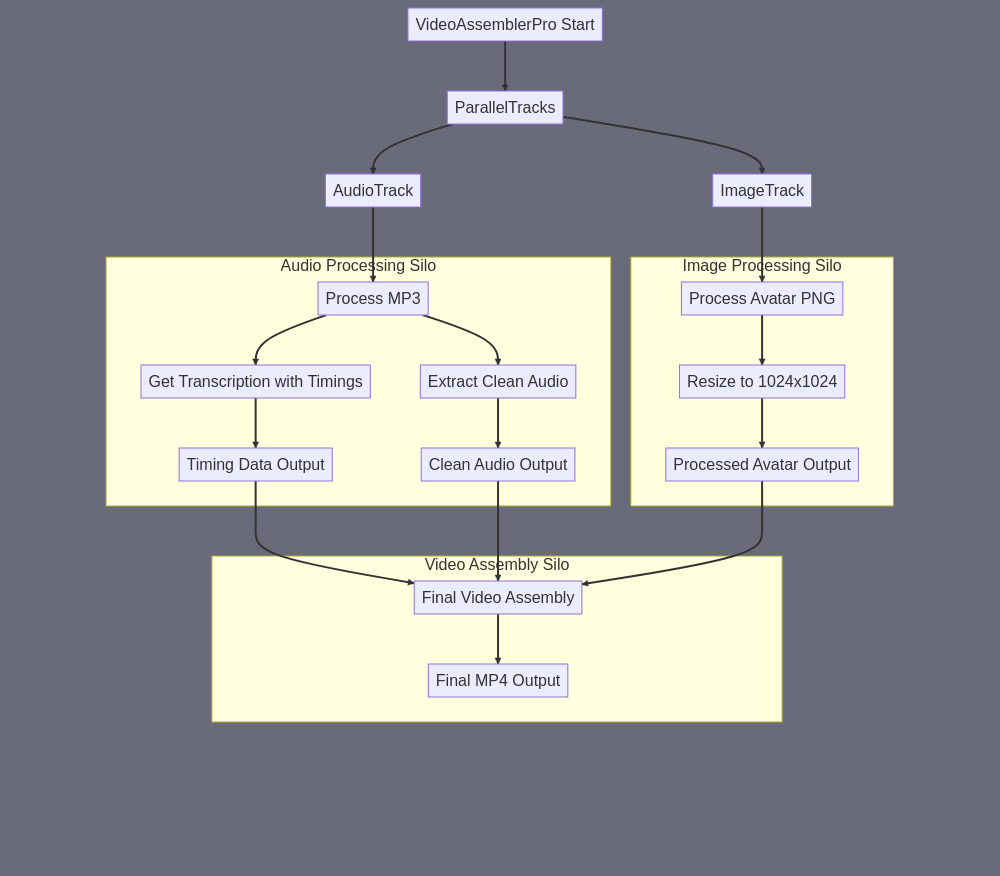
Let me break down the VideoAssemblerPro subagent following the requested format: A) SUBAGENT SUMMARY: A specialized video assembly agent that combines an AI avatar image, voice-over audio, and lip-sync data to create a synchronized talking head video with natural mouth movements and facial expressions. B) FINAL TASK OUTPUT: An MP4 video file (16:9 aspect ratio) featuring the AI avatar speaking with synchronized lip movements, approximately matching the duration of the input audio file, with the avatar centered in frame against a neutral background. C) SUBAGENT INPUT: - PNG URL of the AI-generated avatar image - MP3 URL of the voice-over audio - Text transcription with precise timing data for lip-sync - Optional: Movement/animation instructions E) SUBAGENT TASK SUMMARY: The flow requires multiple parallel processes that merge into the final output: 1. Audio Processing Track: Input MP3 > #198 Get Transcription Of MP3 (With Timings) > Timing Data Input MP3 > #196 Extract MP3 Audio From MP4 File > Clean Audio 2. Image Processing Track: Input Avatar PNG > #191 Resize Image (to 1024x1024) > Processed Avatar 3. Final Assembly: (Timing Data + Clean Audio + Processed Avatar) > #168 Generate Talking Head Video From MP3 & transcription > Final MP4 F) SILOS: SILO 1 - AUDIO PROCESSING - Purpose: Process audio and extract precise timing data - Input: MP3 URL - Skills: #198, #196 - Output: Timing data + cleaned audio SILO 2 - IMAGE PROCESSING - Purpose: Prepare avatar image for video generation - Input: PNG URL - Skills: #191 - Output: Properly sized avatar image SILO 3 - VIDEO ASSEMBLY - Purpose: Combine all elements into final talking head video - Input: All processed components - Skills: #168 - Output: Final MP4 video This workflow takes advantage of existing skills while accommodating the need for precise lip-sync and avatar animation. The #168 skill (Generate Talking Head Video) serves as the crucial final step that brings everything together into a cohesive talking head video.
5 Template & Links
Expand Flow
I notice that you've asked me to analyze "subagent 6" but in the provided list of subagents, there were only 5 subagents listed (ScriptMaster, VoiceForge, AvatarVision, LipSyncWizard, and VideoAssemblerPro). There was no subagent 6 defined. To properly analyze and break down a subagent's workflow, I would need: 1. The specific subagent to analyze (either one of the 5 listed, or details about a new subagent 6) 2. Its intended purpose within the larger workflow 3. Its relationship to the other subagents Could you please clarify: 1. Which specific subagent you'd like me to analyze? (1-5, or details about a new subagent 6) 2. If this is a new subagent 6, what is its intended purpose in the workflow? Once you provide this information, I can give you a detailed breakdown following your requested format with the subagent summary, task output, inputs, task summary, and silos.
6 Template & Links
Expand Flow
Templates & Links Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
7 Template & Links
Expand Flow
Questions & Research Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
8 Template & Links
Expand Flow
Templates & Links Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
9 Template & Links
Expand Flow
Templates & Links Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
10 Template & Links
Expand Flow
Questions & Research Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
11 Template & Links
Expand Flow
Templates & Links Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
12 Template & Links
Expand Flow
Need To Start Afresh?
BACK TO REFINE
Tweaked & Good To Go?
PROCEED TO DEPLOY