Menu
NEW AGENT
MY AGENTS
ASSISTANTS
Step 1:
Video to How To Article
1️⃣
Perfect output
- scan ALL
2️⃣ Add
output numbers
, then...
3️⃣ Add
Subagent Numbers
(work backwards
from output number!
)
4️⃣ Add
ACTUAL Skills
to subagent
✅ DONE..Copy x4 to Step 3...
SETTINGS
LOGOUT
What Shall We Build Next?
1
Describe
Describe your task
2
Refine
Refine the plan
3
SubAgents
Review all agents
4
Deploy
Deploy your agent
Sub Agent 1
Sub Agent 2
Sub Agent 3
Sub Agent 4
Sub Agent 5
Sub Agent 6
Sub Agent 7
Sub Agent 8
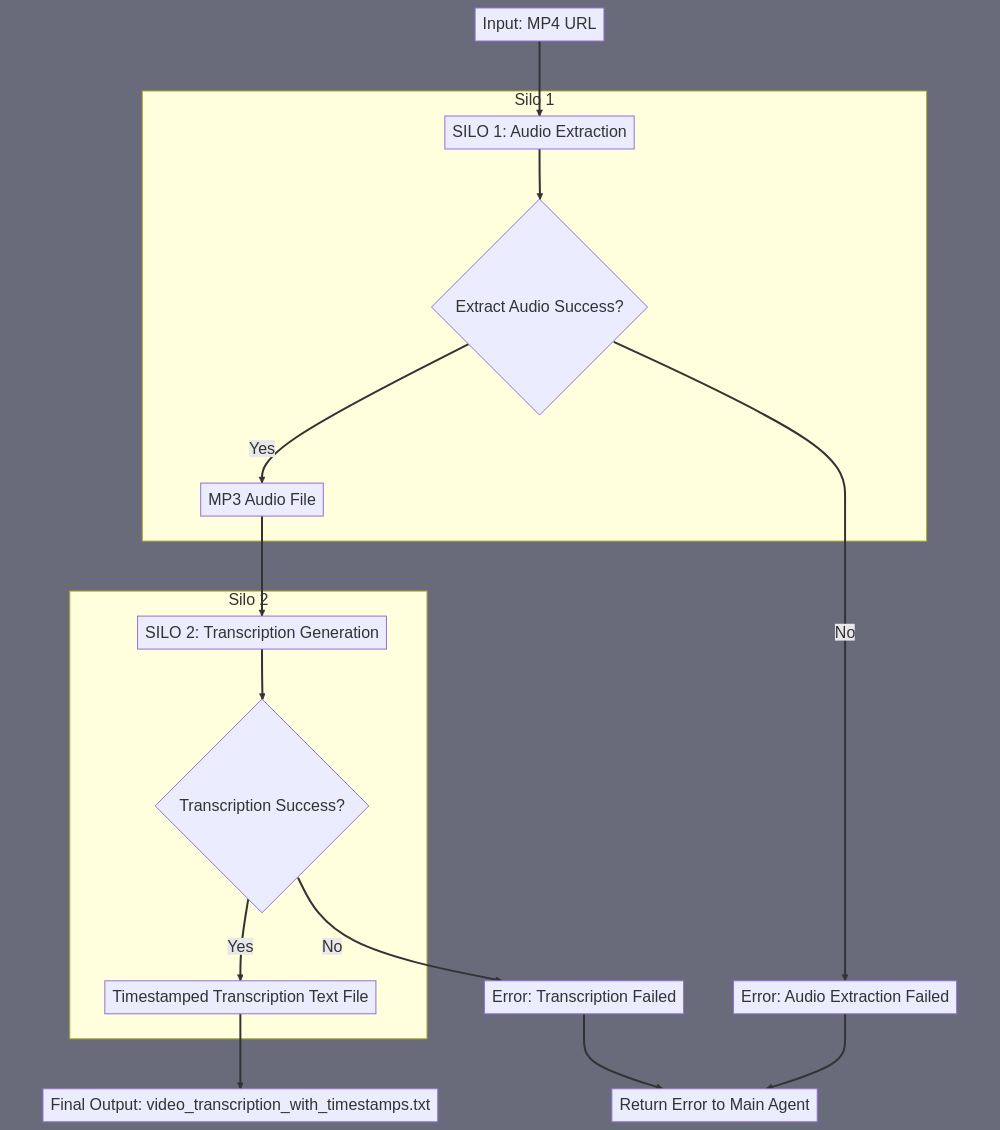
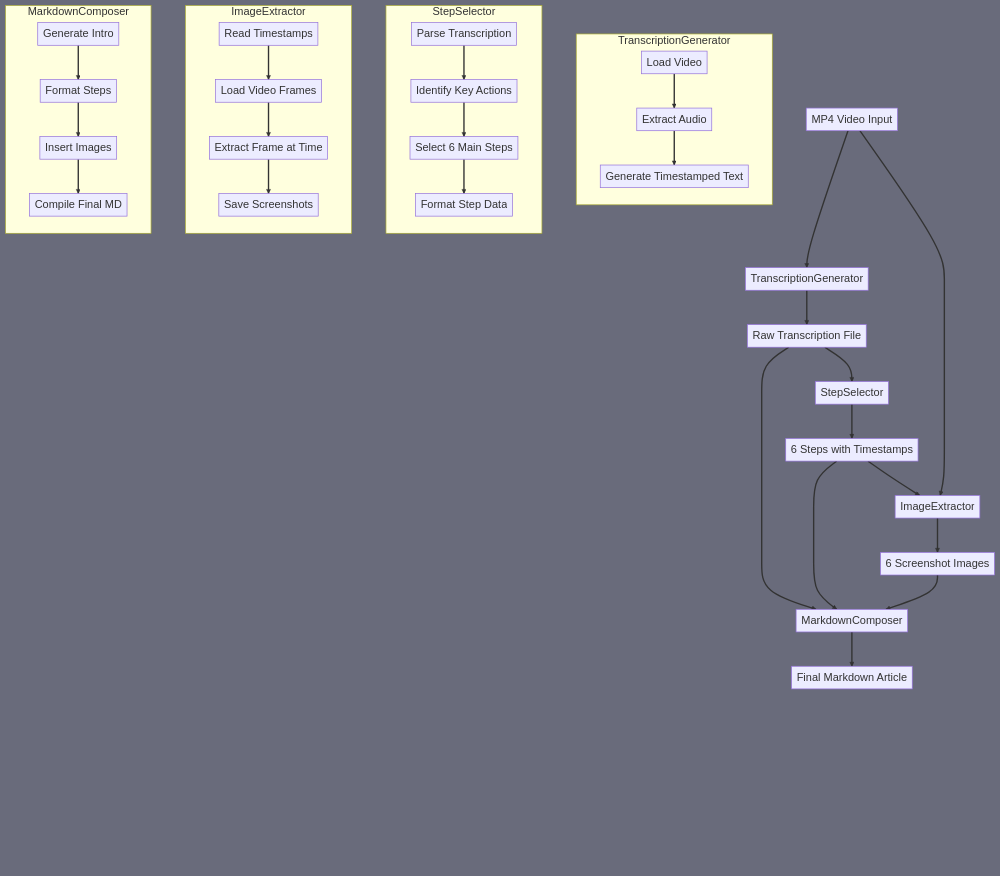
Let me break down the TranscriptionGenerator subagent in detail: A) SUBAGENT SUMMARY: A specialized agent that converts a video tutorial into a precise, timestamp-annotated transcription text file. B) FINAL TASK OUTPUT: A single .txt file containing line-by-line transcription with exact timestamps in the format "[MM:SS.ms] transcribed_text" for each spoken segment (with segments typically 3-8 seconds in length). C) SUBAGENT INPUT: • URL of MP4 video file of the tutorial E) SUBAGENT TASK SUMMARY: This subagent requires two key steps in sequence: 1. First, extract audio from the MP4 (since transcription works better with pure audio) 2. Then generate the transcription from that audio The specific skill chain would be: MP4 URL > #196 (Extract MP3 Audio From MP4 File) > #198 (Get Transcription Of MP3 With Timings) > timestamped transcription .txt file This is actually more efficient than using skill #207 (Get Transcription From MP4 Video URL) directly, because: - The two-step process allows us to verify the audio extraction worked - Skill #198 is specifically optimized for audio transcription - Having the MP3 as an intermediate file gives us a fallback if needed F) SILOS: This subagent has two distinct silos that operate sequentially: SILO 1: AUDIO EXTRACTION • Purpose: Extract clean audio from video • Input: MP4 URL • Skill Used: #196 (Extract MP3 Audio From MP4 File) • Output: MP3 URL SILO 2: TRANSCRIPTION GENERATION • Purpose: Generate timestamped transcription • Input: MP3 URL (from Silo 1) • Skill Used: #198 (Get Transcription Of MP3 With Timings) • Output: Final timestamped transcription .txt file Each silo must complete fully before the next begins, ensuring clean data flow and error checking opportunities between major steps.
SubAgent #1 - Diagram
Expand Diagram
Let me break down the StepSelector subagent following the requested format: A) SUBAGENT SUMMARY: A processing agent that analyzes a video transcription to identify and structure exactly six key instructional steps, with their corresponding timestamps, regardless of how many steps are actually present in the source material. B) FINAL TASK OUTPUT: A single JSON file ("selected_steps.json") containing an array of exactly 6 objects, each with: - step_number (1-6) - title (string, max 60 chars) - description (string, max 200 chars) - timestamp (string in format "MM:SS") C) SUBAGENT INPUT: 1. A text file containing the complete video transcription with timestamps (format: "timestamp: spoken text") 2. Optional: The video's overall topic/purpose (string) E) SUBAGENT TASK SUMMARY: Input > #223 (Initial analysis) > #223 (Step extraction) > #223 (Step refinement) > Output Detailed flow: 1. First #223 call: - INPUT: Full transcription + prompt "Analyze this how-to video transcription and identify all possible instructional steps" - OUTPUT: Unstructured list of all potential steps 2. Second #223 call: - INPUT: Previous output + prompt "Select and consolidate into exactly 6 most important steps, ensuring comprehensive coverage" - OUTPUT: Draft of 6 steps with rough timestamps 3. Third #223 call: - INPUT: Previous output + prompt "Format these 6 steps into JSON structure with exact timestamps, titles, and descriptions" - OUTPUT: Final JSON structure F) SILOS: SILO 1: ANALYSIS - Purpose: Initial processing of transcription - Skill: #223 - Input: Raw transcription - Output: List of all potential steps SILO 2: SELECTION - Purpose: Consolidation to exactly 6 steps - Skill: #223 - Input: Full step list - Output: 6 selected steps with rough timestamps SILO 3: FORMATTING - Purpose: Final JSON structuring - Skill: #223 - Input: 6 selected steps - Output: Properly formatted JSON file This structure ensures that even if the original video contains more or fewer steps, the output will always be exactly 6 well-structured, logical steps that cover the entire tutorial process. Each silo builds upon the previous one, with the LLM (#223) being used in increasingly specific ways to refine and structure the content. The final output is guaranteed to be consistent with the required JSON format for use by subsequent subagents.
SubAgent #2 - Diagram
Expand Diagram
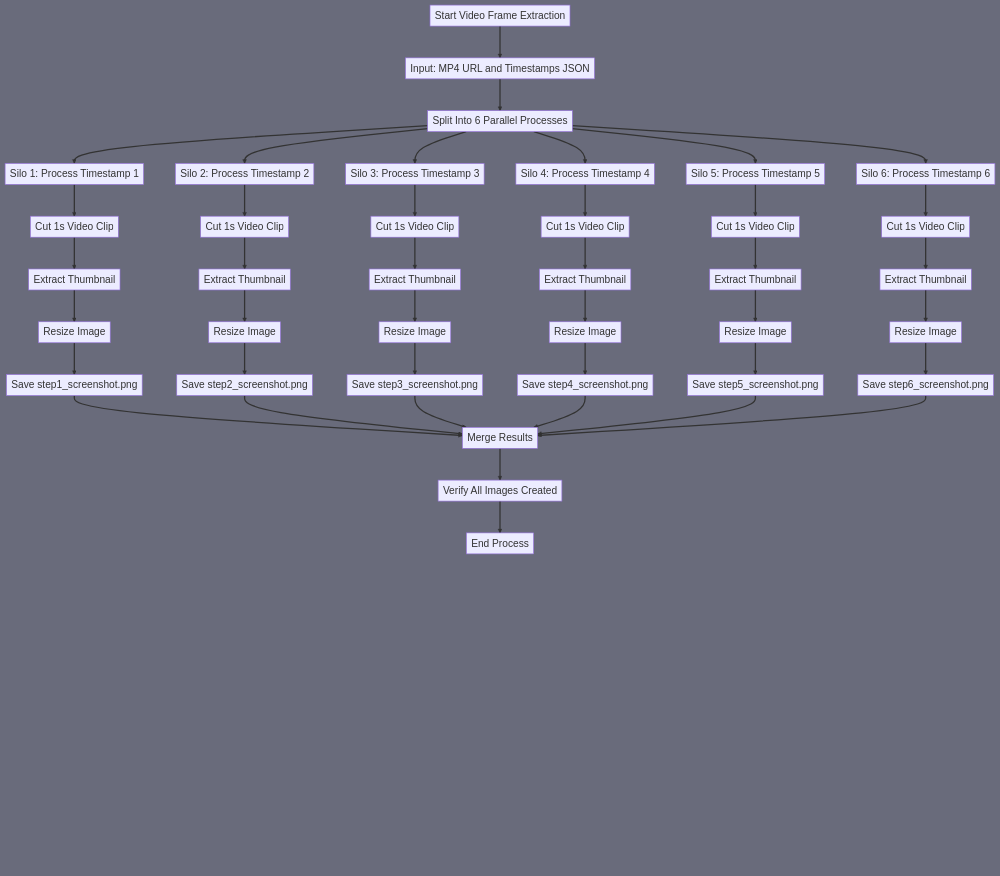
Let me break this down according to your format: A) SUBAGENT SUMMARY: A specialized image extraction agent that takes an MP4 video file and six specific timestamps, extracting high-quality PNG screenshots at each timestamp and saving them in a structured way. B) FINAL TASK OUTPUT: Six individual PNG image files, named "step1_screenshot.png" through "step6_screenshot.png", stored in an "images/" directory, each representing a key moment from the tutorial video at specific timestamps. C) SUBAGENT INPUT: 1. URL of the MP4 video file 2. JSON file containing six timestamps (format: "selected_steps.json" with structure like {"step1": {"timestamp": "00:23:39"}, ...}) E) SUBAGENT TASK SUMMARY: The process requires multiple steps because there's no direct "extract frame at timestamp" skill. Here's the chain: 1. For each timestamp: a. Use Skill #194 (Cut Small Section From MP4 Video) to extract a 1-second clip at the timestamp b. Use Skill #202 (Extract Thumbnail Images Of MP4 Video) to get a clear frame c. Use Skill #191 (Resize Image) to ensure consistent image dimensions F) SILOS: Since we need to extract six different images, this naturally breaks into six parallel silos, each following the same pattern: SILO 1 (Step 1 Image): ``` Input: MP4 URL + Timestamp 1 > #194 Cut video section (1 sec) at timestamp 1 > #202 Extract thumbnail (with prompt "extract clearest frame") > #191 Resize to 1280x720 Output: step1_screenshot.png ``` SILO 2 (Step 2 Image): ``` Input: MP4 URL + Timestamp 2 > #194 Cut video section (1 sec) at timestamp 2 > #202 Extract thumbnail (with prompt "extract clearest frame") > #191 Resize to 1280x720 Output: step2_screenshot.png ``` [SILOS 3-6 follow identical pattern] Each silo operates independently but follows the same workflow, ensuring we get six consistently-sized, high-quality screenshots from the exact moments needed in the tutorial video. The image resizing at the end ensures all screenshots are uniform in dimensions for the final article layout. Note: While it might seem inefficient to extract 1-second clips first, this approach gives us the most precise control over the exact frame we want to capture, as the thumbnail extraction can then pick the clearest frame from that precise moment. The final output will be six PNG files, all consistently sized, named systematically, and ready for the MarkdownComposer agent to embed them in the article.
SubAgent #3 - Diagram
Expand Flow
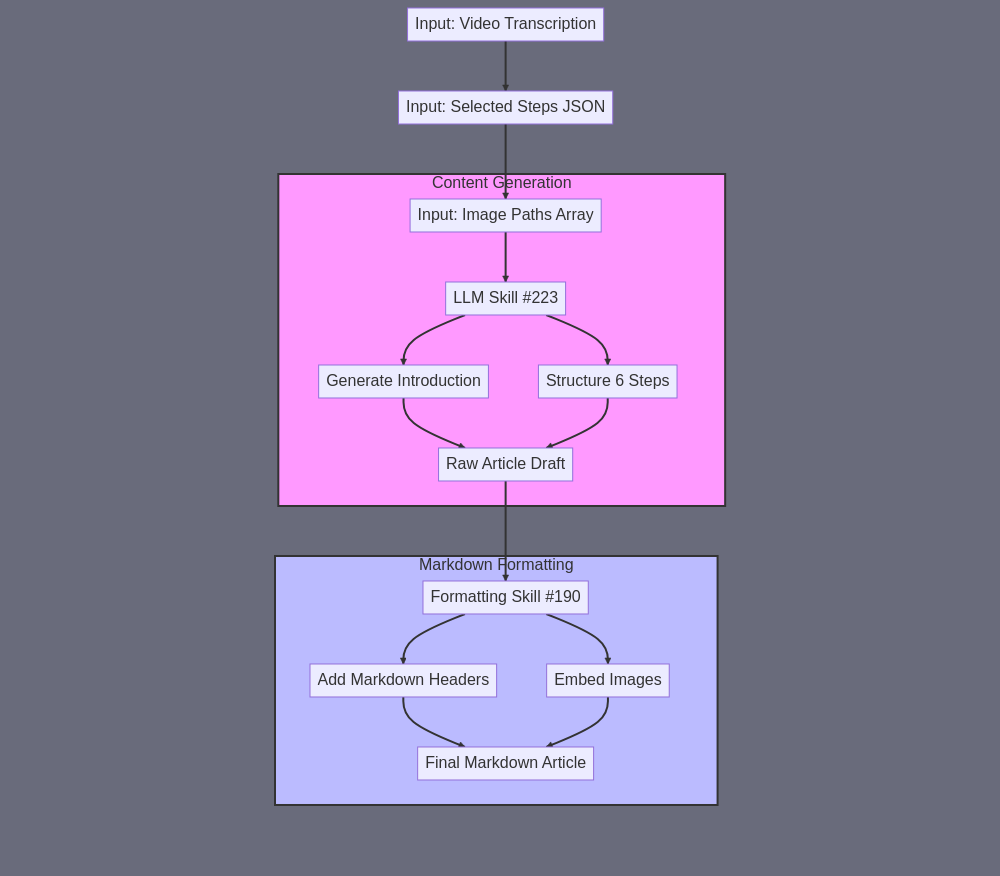
Let me break down this MarkdownComposer subagent in detail. A) SUBAGENT SUMMARY: A specialized composer that takes transcription data, step information, and image paths to generate a complete, formatted Markdown article with exactly six steps and embedded images. B) FINAL TASK OUTPUT: A single Markdown (.md) file containing: - Introduction (100-200 words) - 6 numbered steps - 6 embedded image references in correct Markdown syntax - Consistent formatting throughout - Filename: "how_to_article.md" C) SUBAGENT INPUT: 1. video_transcription_with_timestamps.txt (full transcription file) 2. selected_steps.json (containing 6 steps with timestamps) 3. Array of 6 image file paths (eg. ["images/step1.png", "images/step2.png", etc]) E) SUBAGENT TASK SUMMARY: The workflow will use two main skills in sequence: 1. First Pass - Generate Article Structure: ``` Input: transcription + steps.json > #223 (Powerful LLM) with prompt to structure article > Output: Initial article draft ``` 2. Second Pass - Format and Embed Images: ``` Input: Initial draft + image paths > #190 (Write/rewrite text) with formatting instructions > Output: Final markdown with proper image embedding ``` F) SILOS: The subagent operates in two distinct silos: SILO 1: CONTENT GENERATION • Purpose: Create the article's textual content • Skill: #223 (Powerful LLM) • Input: - video_transcription_with_timestamps.txt - selected_steps.json • Prompt Instructions: - "Generate a how-to article with: 1. Brief introduction explaining purpose 2. Exactly 6 steps based on the provided JSON 3. Each step should be 2-3 sentences 4. Maintain consistent technical tone" • Output: Raw article text SILO 2: MARKDOWN FORMATTING • Purpose: Format content with proper Markdown syntax • Skill: #190 (Write/rewrite) • Input: - Raw article text from Silo 1 - Array of 6 image paths • Prompt Instructions: - "Format the article in Markdown with: 1. # for main title 2. ## for each step 3. Insert  after each step heading 4. Consistent spacing between sections" • Output: Final how_to_article.md file This approach separates content generation from formatting, ensuring clean, consistent output while maintaining proper Markdown syntax and image embedding.
4 Template & Links
Expand Flow
I notice that you've asked me to analyze "subagent 5", but in the provided workflow there are only 4 subagents (TranscriptionGenerator, StepSelector, ImageExtractor, and MarkdownComposer). There is no subagent 5 defined in the original workflow. Would you like me to: 1. Analyze one of the existing four subagents in detail 2. Suggest a potential fifth subagent that might enhance the workflow 3. Clarify which specific subagent you'd like me to focus on Please let me know which option you'd prefer, and I'll provide a detailed analysis following the format you've outlined (with Subagent Summary, Final Task Output, Subagent Input, Task Summary, and Silos).
5 Template & Links
Expand Flow
I notice that you haven't actually specified which subagent you want me to analyze - you provided a placeholder that says "no agent found for subagent 6". Additionally, in the original list of subagents, there were only 4 subagents described (TranscriptionGenerator, StepSelector, ImageExtractor, and MarkdownComposer). To properly analyze a subagent and create its workflow, I'll need you to specify which of these subagents you want me to focus on, or if there's a different subagent you'd like me to analyze. Could you please clarify which specific subagent you'd like me to break down? Once you specify the subagent, I can provide a detailed analysis following your requested format: A) SUBAGENT SUMMARY B) FINAL TASK OUTPUT C) SUBAGENT INPUT E) SUBAGENT TASK SUMMARY F) SILOS Please let me know which subagent you'd like me to analyze, and I'll provide a complete workflow breakdown.
6 Template & Links
Expand Flow
Templates & Links Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
7 Template & Links
Expand Flow
Questions & Research Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
8 Template & Links
Expand Flow
Templates & Links Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
9 Template & Links
Expand Flow
Templates & Links Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
10 Template & Links
Expand Flow
Questions & Research Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
11 Template & Links
Expand Flow
Templates & Links Lorem Ipsum is simply dummy text of the printing and typesetting industry. Lorem Ipsum has been the industry's standard dummy text ever since the 1500s, when an unknown printer took a galley of type and scrambled it to make a type specimen book. It has survived not only five centuries, but also the leap into electronic typesetting, remaining essentially unchanged. It was popularised in the 1960s with the release of Letraset sheets containing Lorem Ipsum passages, and more recently with desktop publishing software like Aldus PageMaker including versions of Lorem Ipsum.
12 Template & Links
Expand Flow
Need To Start Afresh?
BACK TO REFINE
Tweaked & Good To Go?
PROCEED TO DEPLOY